
Now that we've learned about classification, you may be wondering: how would we be able to create an algorithm for it? Let's work one out through an example. Let's say we're trying to classify whether a tumor is benign (harmless) or malignant (dangerous) solely given its size. For the sake of keeping everything numerical, we can assign a value of 0 to represent benign and a value of 1 to represent malignant. Our data could look something like this:
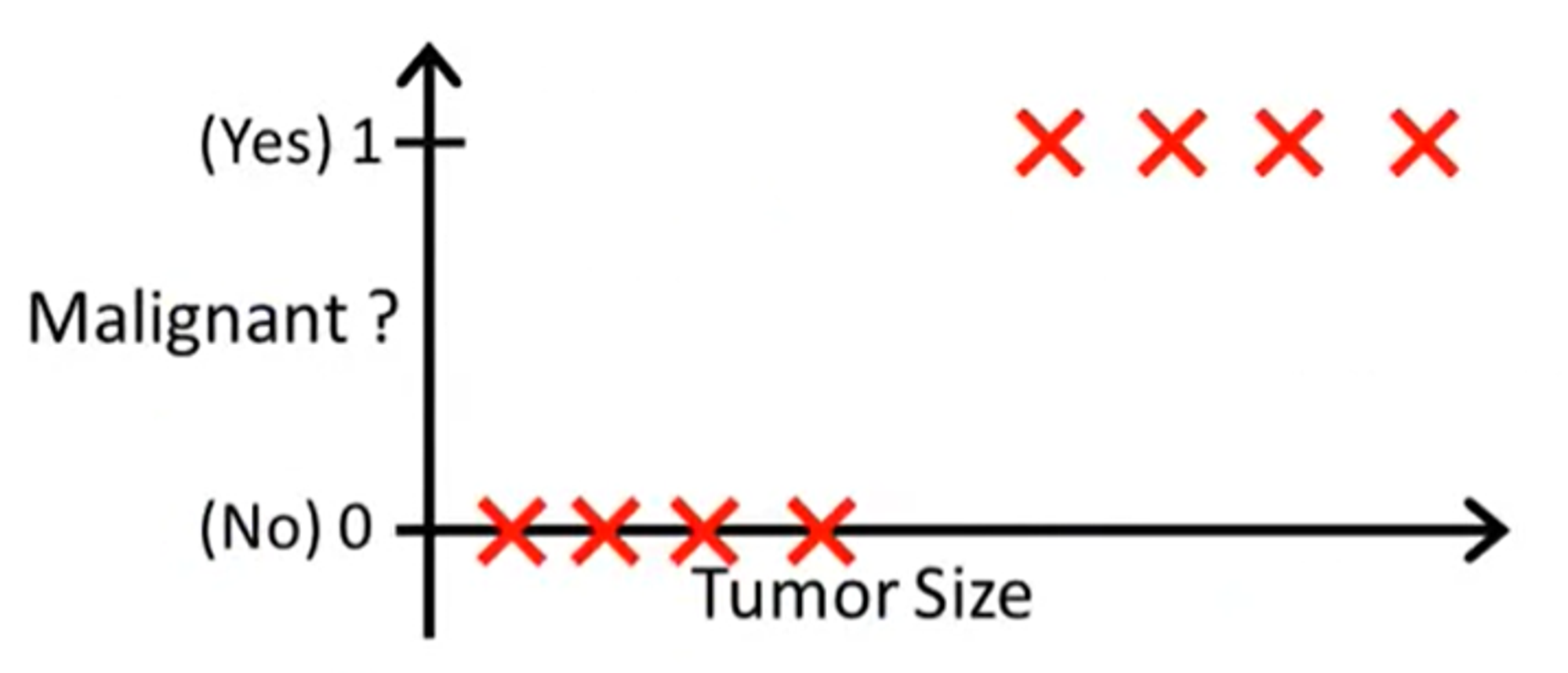
Here, we can see that the four leftmost data points with the smallest tumor sizes aren't malignant, whereas the data points with the largest tumor sizes are malignant. Obviously, real life data sets for tumor classification aren't going to be this simple, but given data like this, how could we go about creating a decision boundary to classify new sets of data? Well, since we've already done so much with linear regression, why not try it out for classification?
Linear Regression Approach
Let's first run linear regression on our data and draw the line of best fit.
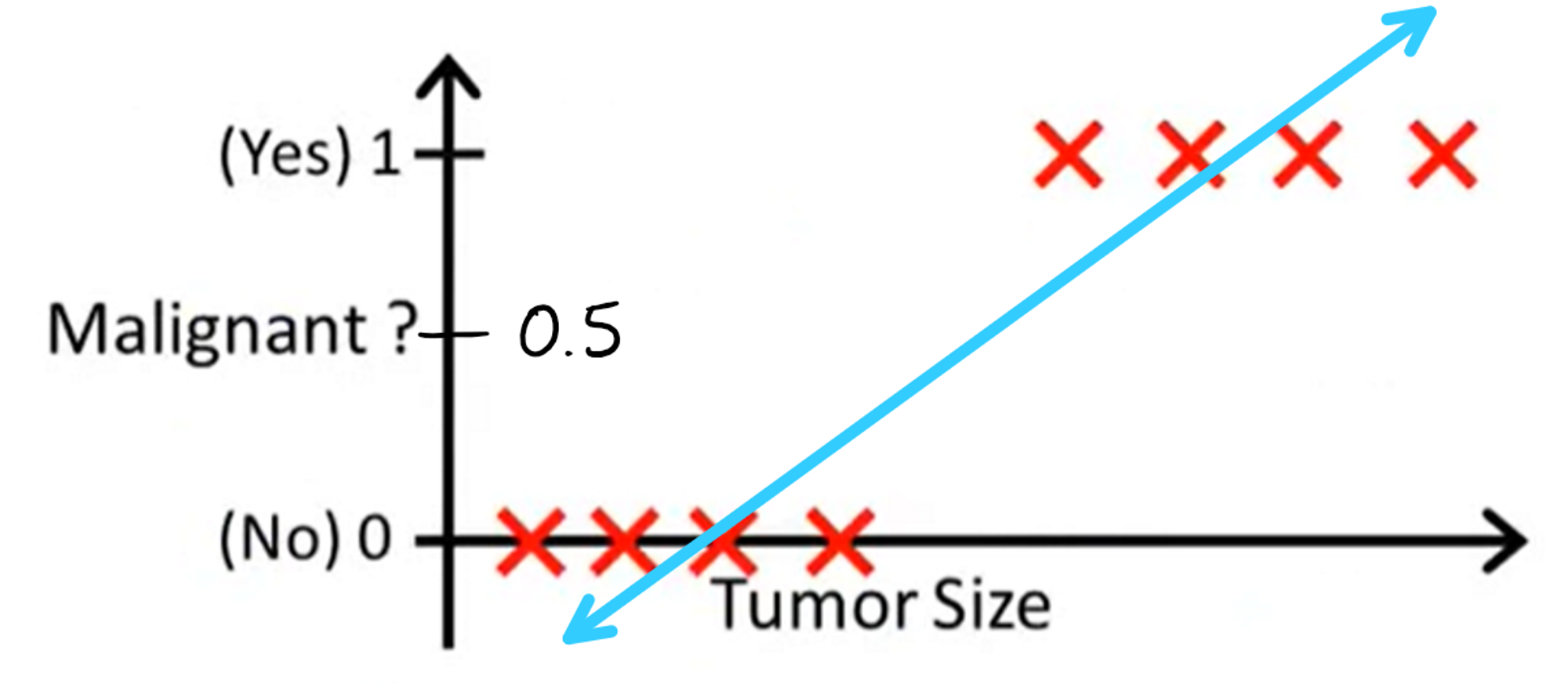
Now how exactly would we use this line to create classifications? One way we could do so is through the following metric: if the y-value of the line is greater than 0.5 at a given tumor size, we classify the tumor as malignant. Otherwise, we classify the tumor as benign. With this model, our decision boundary would look something like this:
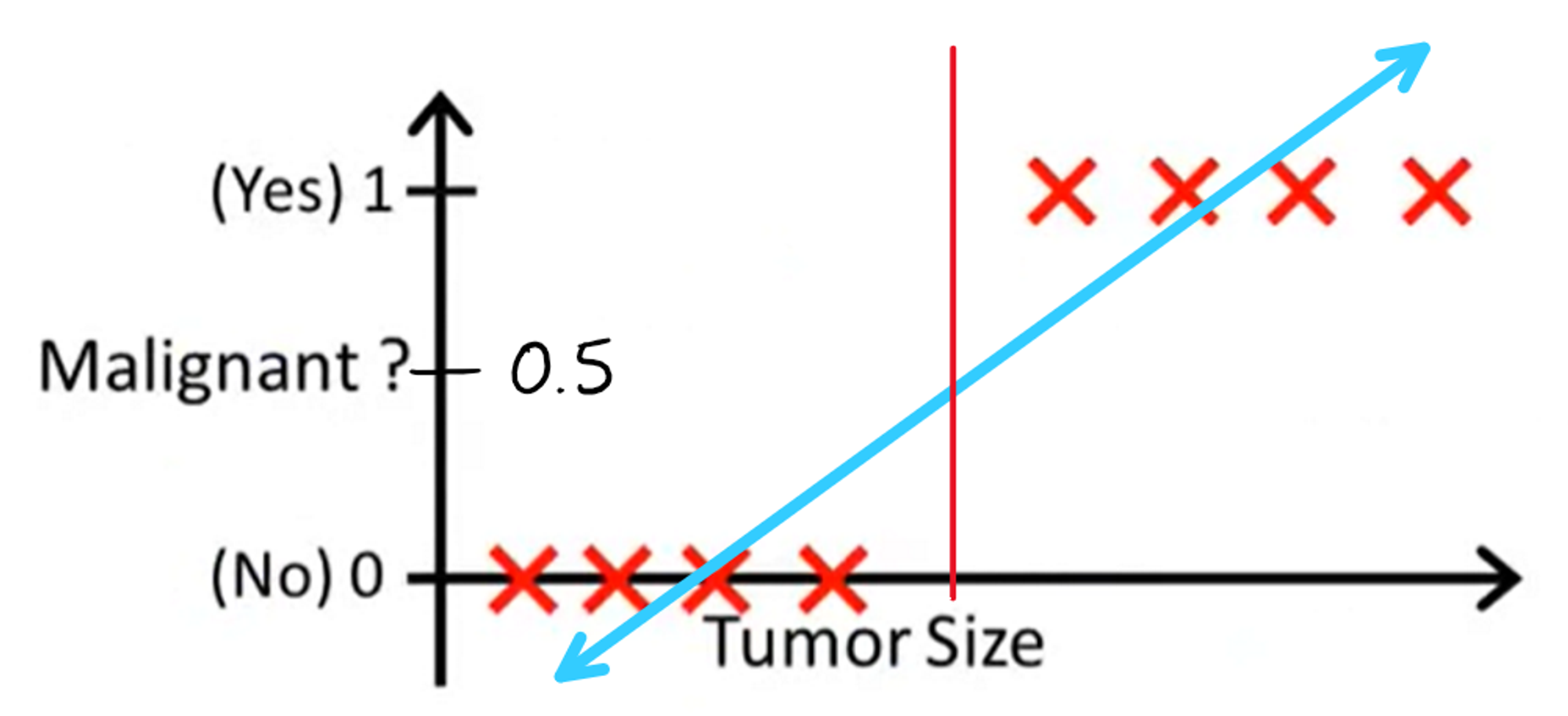
Anything to the left of the red line will be classified as benign and everything to the right will be classified as malignant. This looks like a reasonable decision boundary; it seems like linear regression could actually work!
Unfortunately, however, there is an issue with this approach. Let's say we added a new data point as circled below:
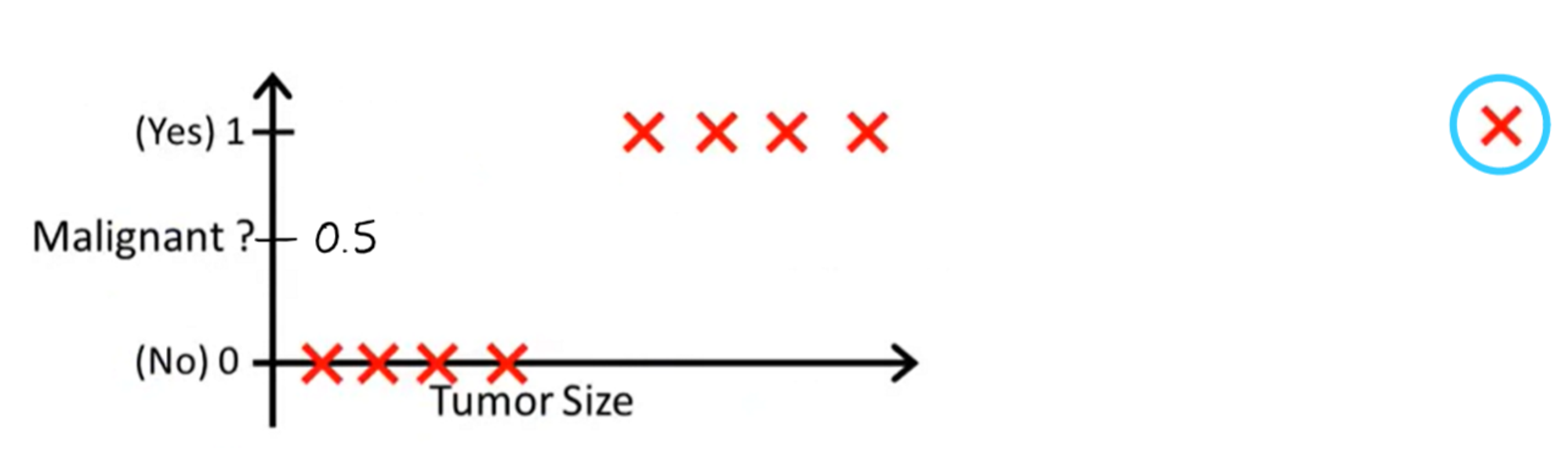
It would seem like adding this point should strengthen the decision boundary that we made up above, as a really large tumor was found to be malignant, which fits perfectly into the boundary. But let's see what happens when we re-draw the line of best fit and decision boundary to incorporate this new data point:
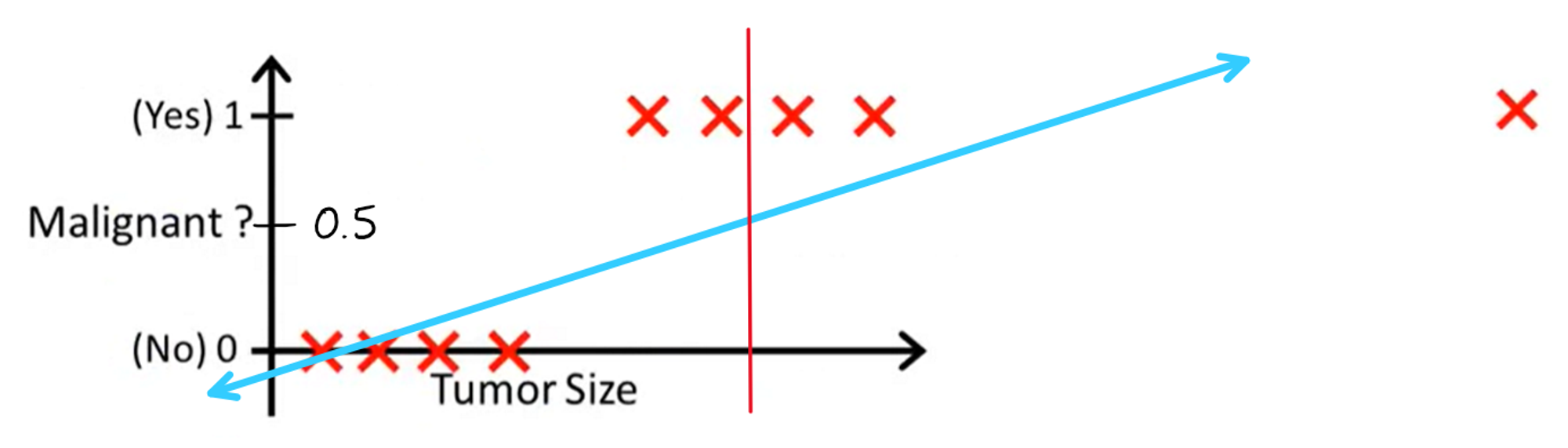
Uh oh, because of this new point, two of the points that are supposed to be classified as malignant are now being classified as benign, even though our new point should have strengthened the previous decision boundary. Unfortunately, there is no way to overcome this downfall with linear regression, and that's what motivates us to use a different algorithm — logistic regression.
Next Section
2.2 Classification with Logistic RegressionCopyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.