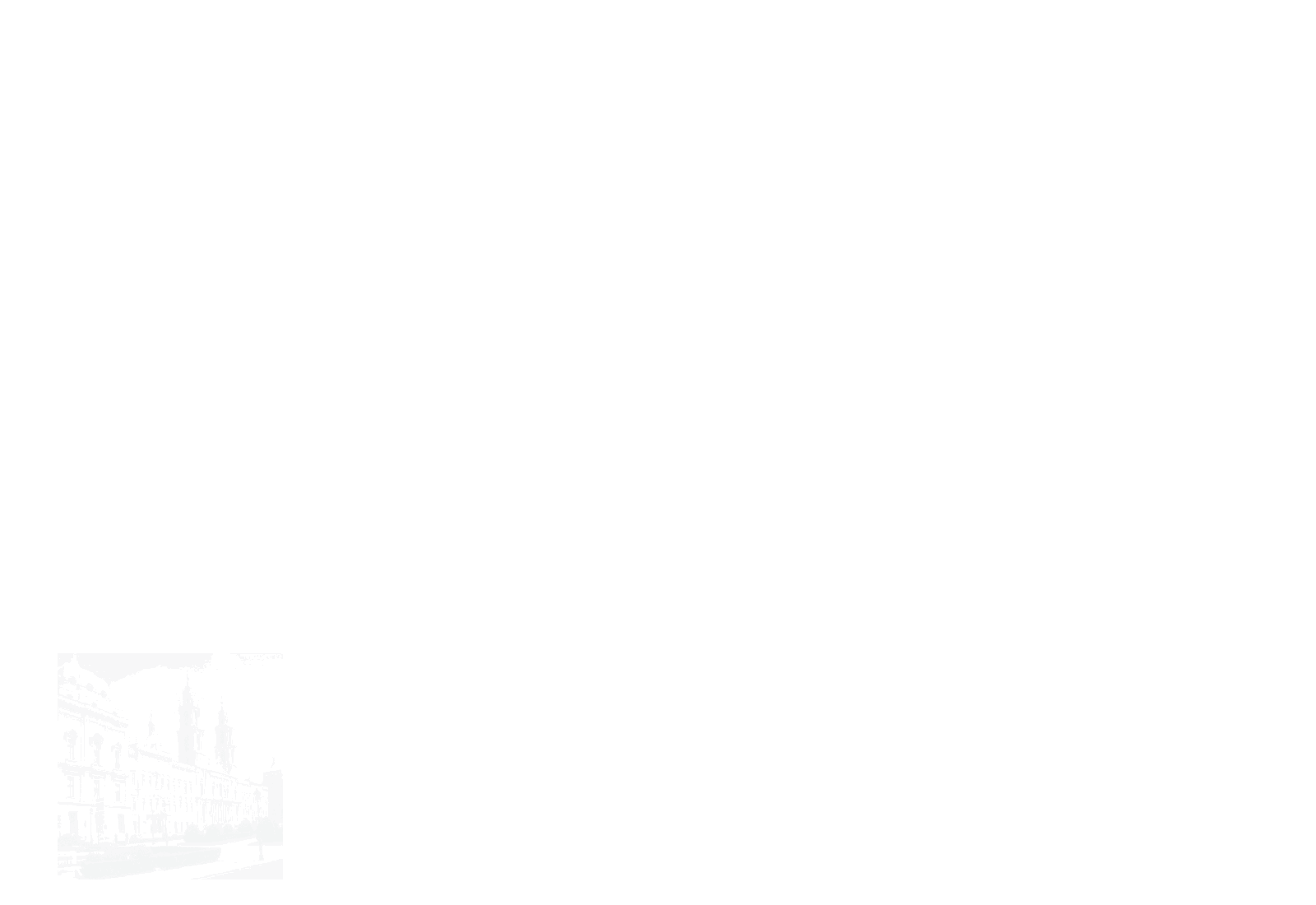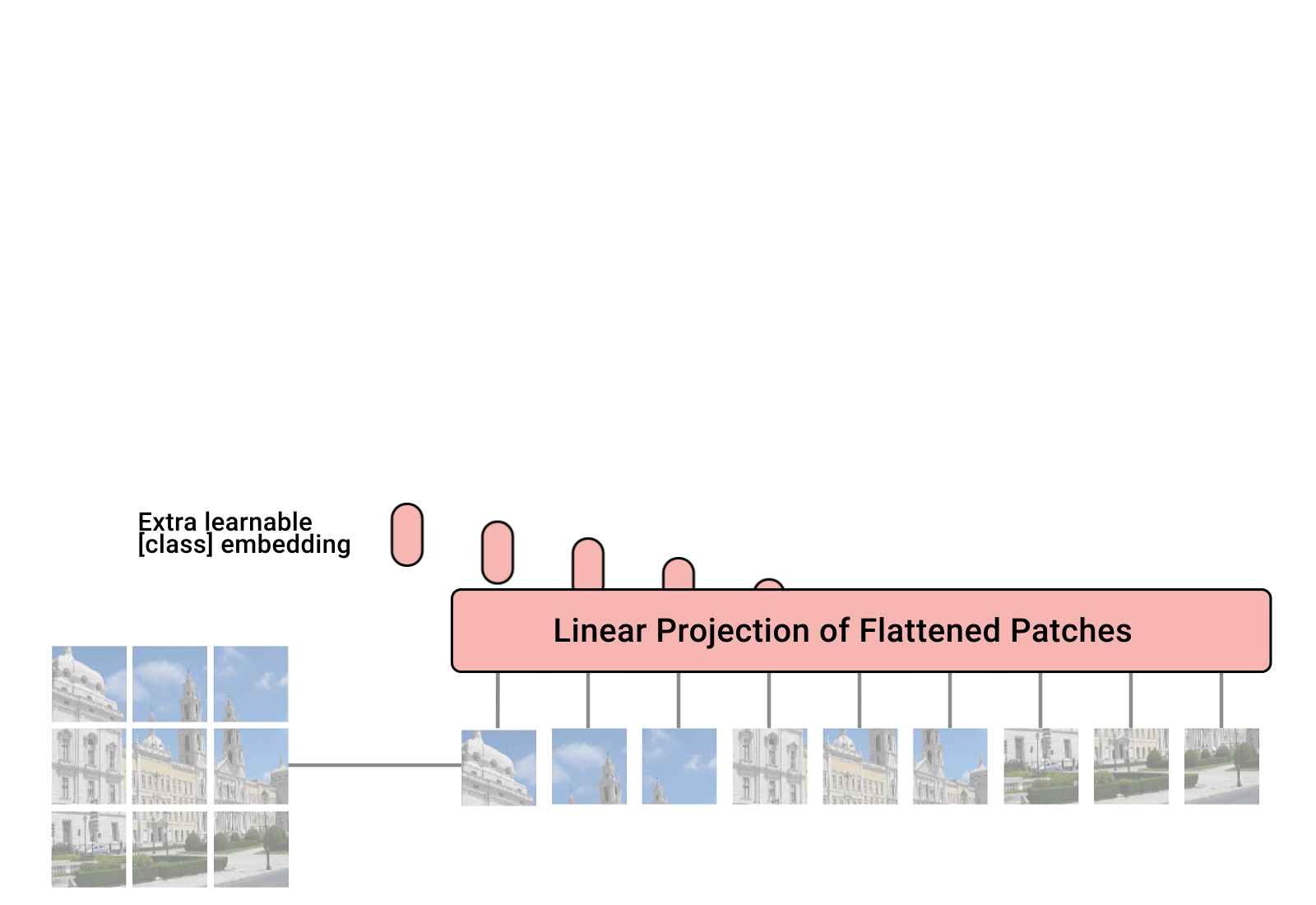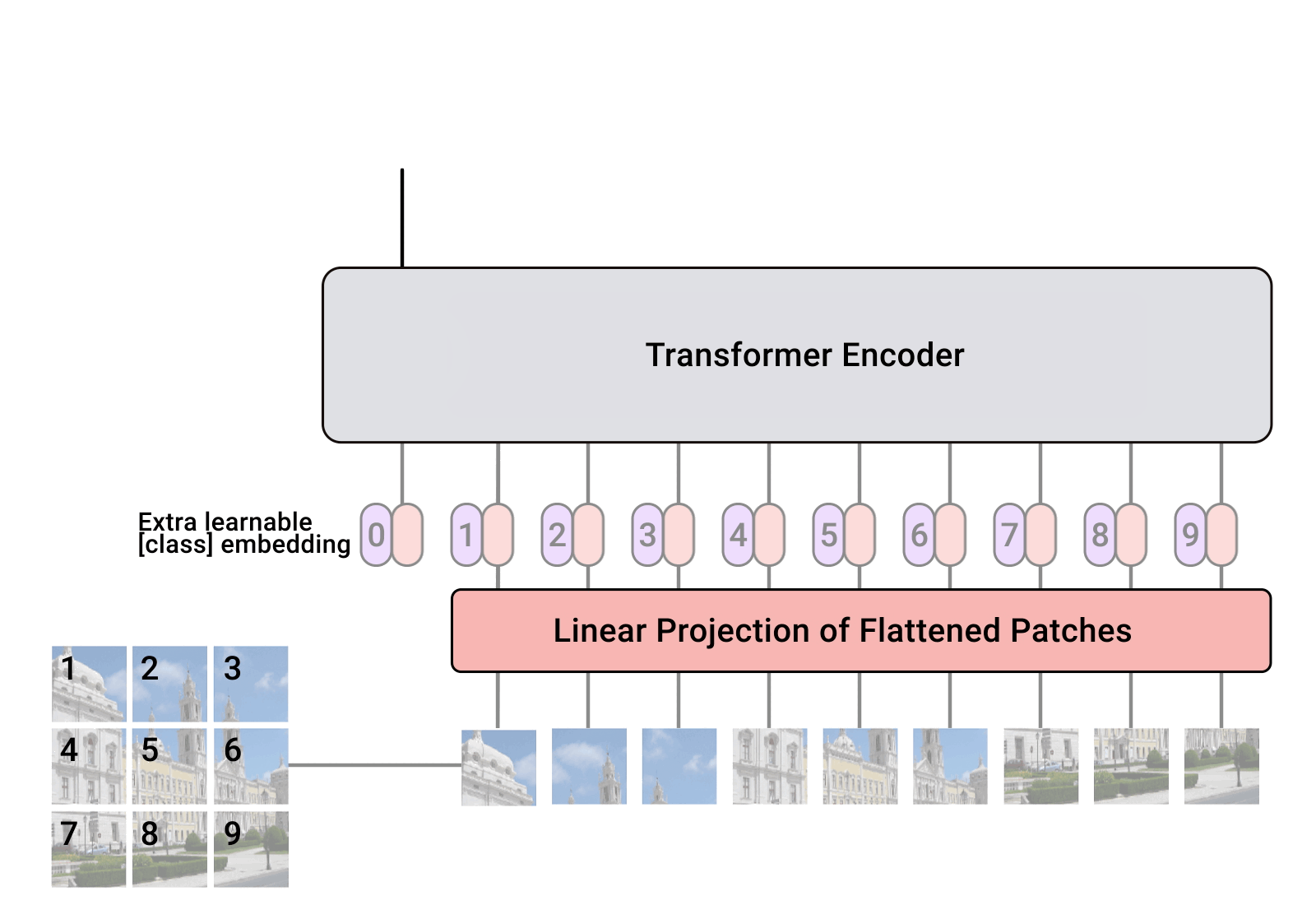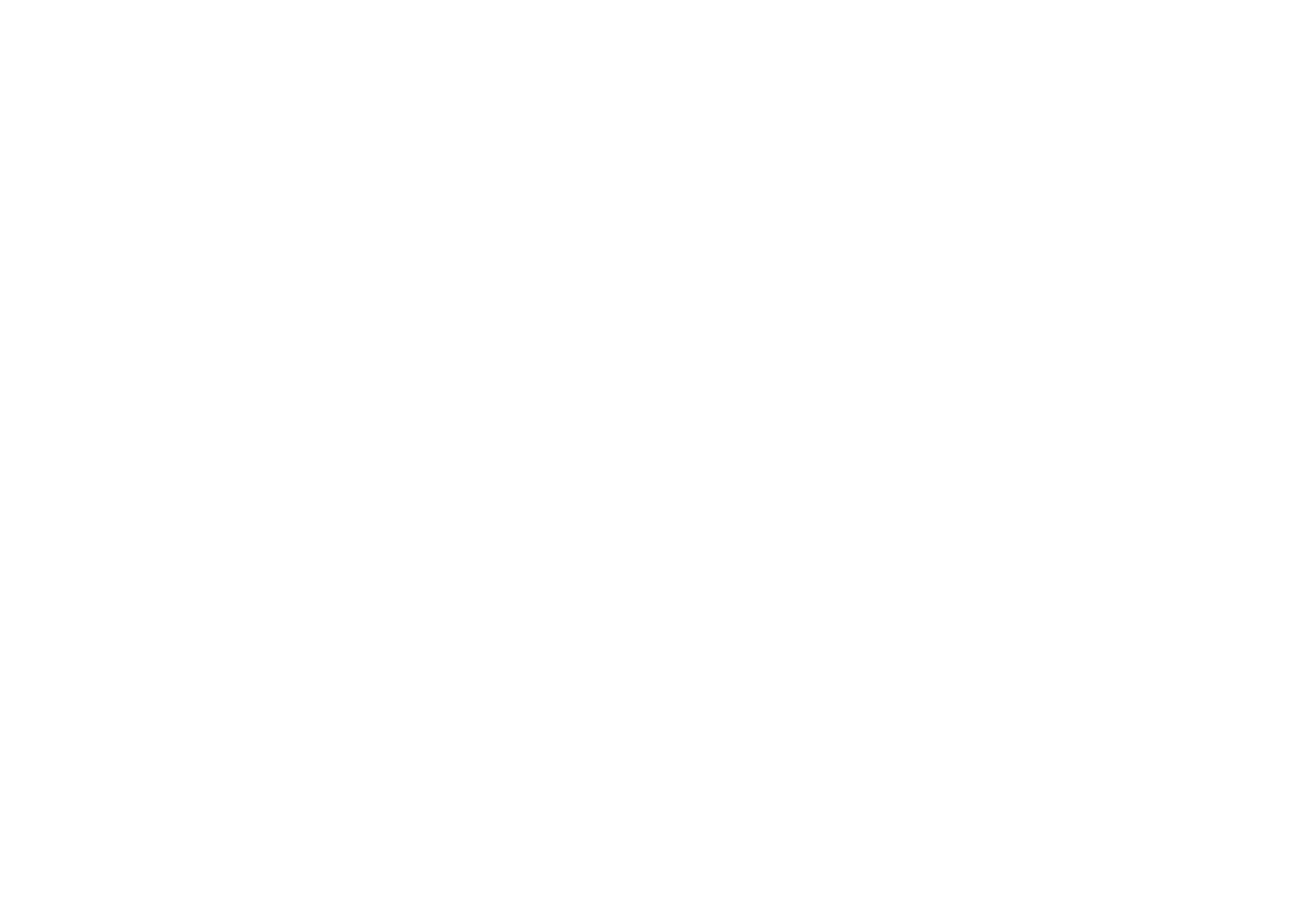
Concept
Vision Transformers work by splitting an image up into multiple little squares, called patches. These patches are then embedded, just like with text embeddings, and then fed into a transformer network. Finally, the output of the transformer is fed into a MLP, which spits out an output. In the animation above, you can see the image being split up into patches, the embeddings being attached, and the rest of the process.
Transformer vs CNN
Transformers aren’t much better than CNNs for classification tasks with small amounts of data, however, when there is a lot of data, transformers are significantly better. This is because of the learnable embeddings - they allow the transformer to understand the relationship between the different pixels, which means that it can understand where an object it in space. This means that when a transformer sees lots of pictures of a dog, it will understand that there is a dog, but a CNN might not understand that. In fact, there is a high likelihood that a CNN will think that an image has a label dog because of a tree in the background, not the dog itself. This concept is illustrated in the picture below - the transformer outlines the shape of the dog, showcasing its understanding that there is a dog in the image.

Previous Section
Copyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.